Interpretable Surgical Navigation via Vision-Langauge-Action Model
Minimally Invasive Surgery and Image-Guided Surgery
With the advent of minimally invasive surgery (MIS), substantial efforts have been devoted to reducing patient burden and accelerating recovery through smaller incisions and specialized surgical instruments. Laparoscopic and robotic surgery serve as prime examples of MIS, and these techniques are rapidly advancing in tandem with image-guided intervention systems that enable precise surgical procedures.
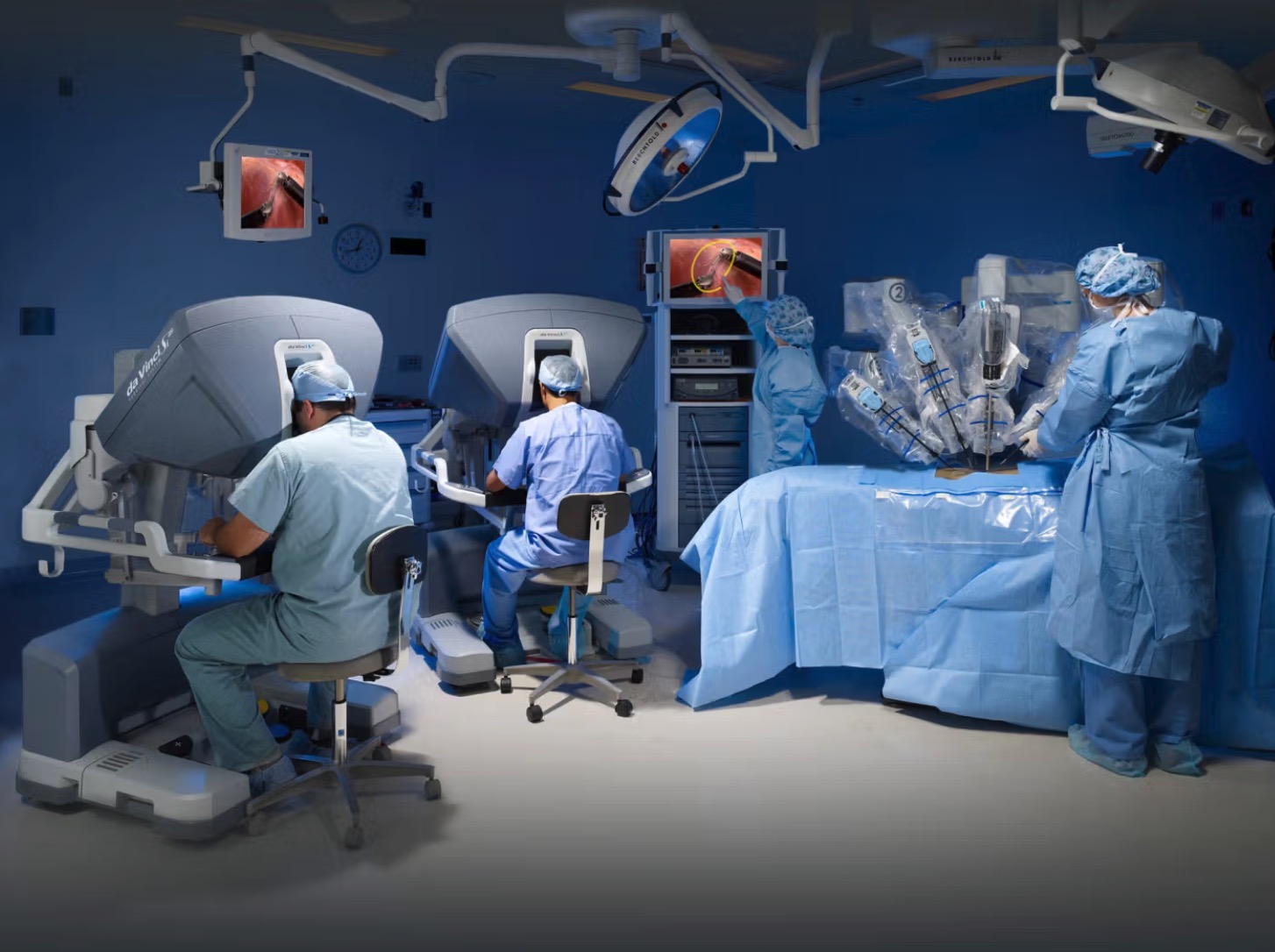
Image-guided intervention encompasses a range of technologies and methodologies designed to ensure accurate, safe procedures while minimizing patient trauma. Specifically, these methods facilitate precise targeting of tumors or lesions using medical imaging to pinpoint the exact location of interest, and structure preservation by providing near-real-time visualization of critical anatomical structures—such as blood vessels, nerves, and major organs—to reduce unnecessary damage. Additionally, they seek to enhance procedural efficiency by shortening operating time, minimizing complications, and thus promoting faster patient recovery.
Among the earliest and most representative image-guided approaches is CT-based surgical planning. For instance, in a tumor resection procedure, a preoperative CT scan allows surgeons to identify the tumor and surrounding anatomical structures, enabling a detailed surgical plan. However, this approach has several well-known limitations. First, surgeons must mentally reconstruct 3D structures from 2D CT slices; second, it is challenging to adapt to real-time anatomical shifts during surgery. Furthermore, discrepancies may arise from differences between the patient’s posture during imaging and actual operating conditions, as well as organ motion due to respiration.
Surgical Simulation & Navigation at Hutom
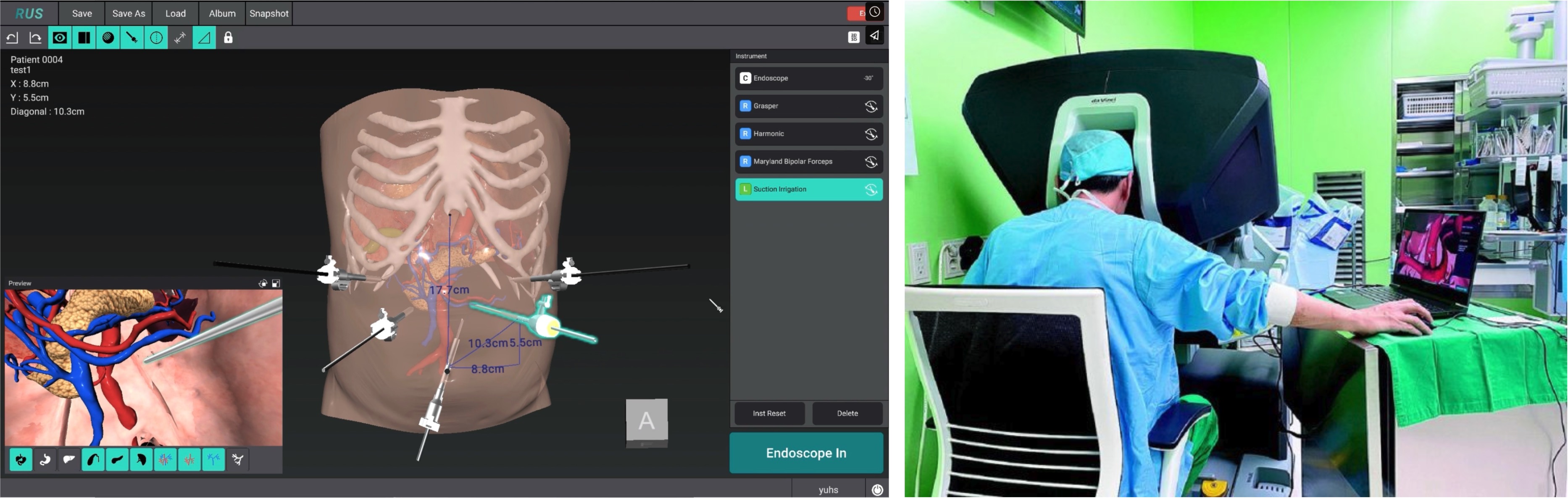
To address these challenges, various imaging and navigation technologies have recently been explored. At Hutom, one such effort focuses on segmenting target anatomy from CT slices acquired before surgery, then reconstructing that anatomy in a 3D model that clinicians can readily interpret. This tool, RUS (a patient’s 3D reconstructed anatomy simulator), assists in precise surgical planning during the preoperative phase and also functions as a navigation tool intraoperatively. Clinicians can directly explore the relevant anatomical structures and manipulate or inspect them in real time using a mobile device equipped with a display, thereby improving visibility and intuitive control in the clinical environment.
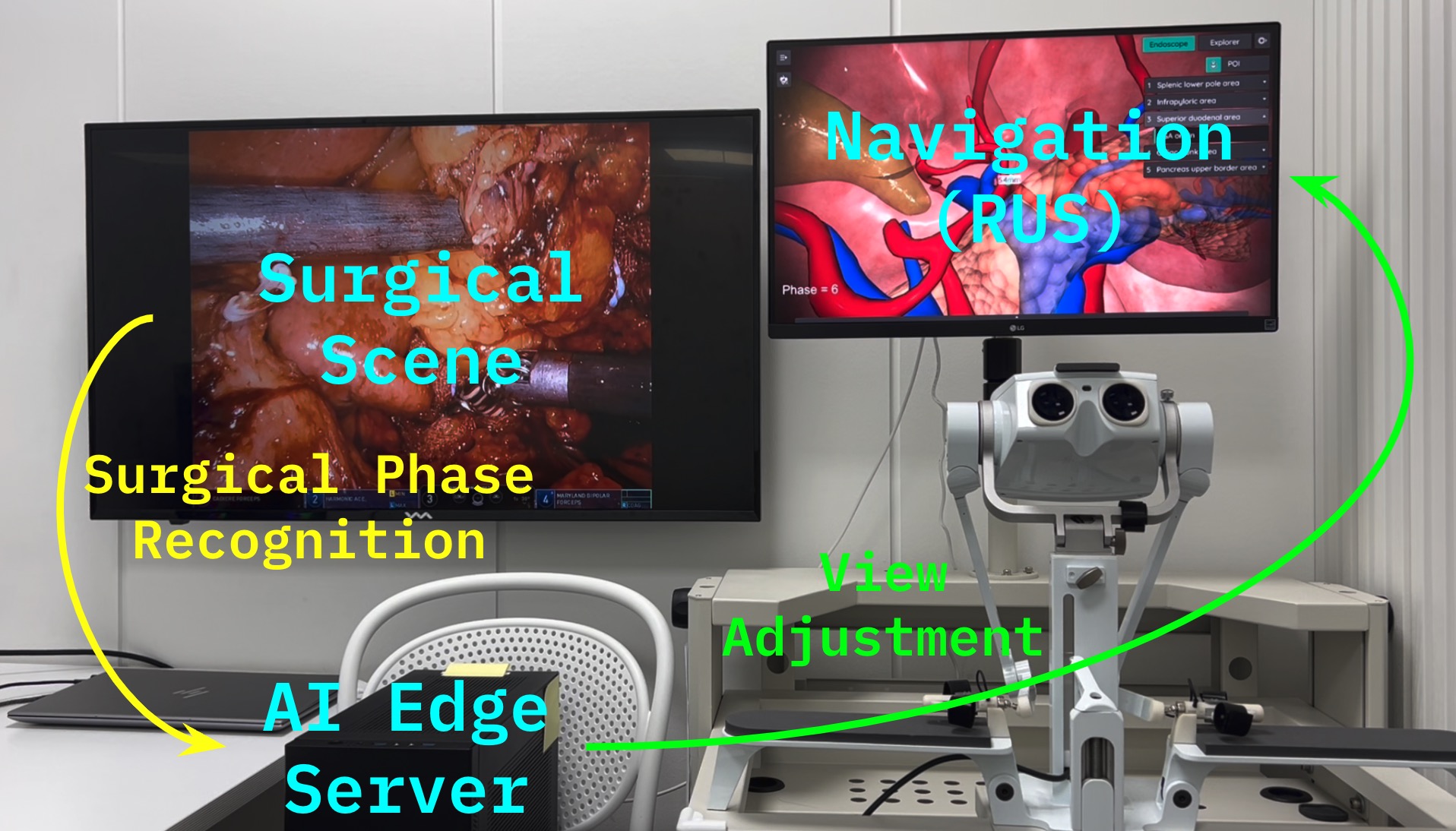
In addition, Hutom has introduced SP-NAS (Surgical Phase Recognition-based Navigation Adjustment System) to automate the navigation workflow. This system leverages an action recognition model to identify the current surgical phase in real time, then automatically adjusts and displays the relevant anatomical information or view required at each phase. By simplifying decision-making and increasing operative efficiency, SP-NAS is expected to enhance patient safety and improve surgical accuracy.
Vision-Language-Action Models for Surgery
Recent advances in Large Language Models (LLMs) have opened up significant possibilities for Agentic AI. Models such as ChatGPT, Claude, and Cursor demonstrate human-like conversational and reasoning capabilities, while LLM-driven agents are also being actively developed in autonomous driving (e.g., Wayve’s LINGO-2) and robotics (e.g., FigureAI’s Helix). A key advantage of these agents is their emergent or near-zero-shot competence, meaning they can perform high-level reasoning even in tasks or scenarios for which they were not explicitly trained.
In the surgical domain, the definition of tasks can be vague, procedures can be lengthy, and a wide range of variations may occur during operations. Conventional scene-understanding models struggle to capture such long, complex temporal contexts. To overcome these challenges, some researchers have turned to vision-language pre-training in order to build more robust multi-modal representations. For instance, models trained on large-scale surgical videos and text data could learn to infer relationships among anatomical structures, surgical phases, and instruments—thereby pushing beyond the limitations of existing surgical recognition models. Ultimately, the goal is to enable context-aware decision-making and action recommendations, paving the way for agentic functionalities.
Such Vision-Language-Action models form the core of our proposed “Interpretable Surgical Navigation via VLA.” By comprehensively understanding surgical video, interpreting its context via language, and, ultimately, providing phase-specific surgical guidance or automatic navigation, these models offer significant potential for improving the precision and interpretability of surgical navigation systems. Through this approach, we aim to further refine and render interpretable navigation systems based on Surgical Phases, advancing the state of the art in minimally invasive and image-guided surgery.
Methodology
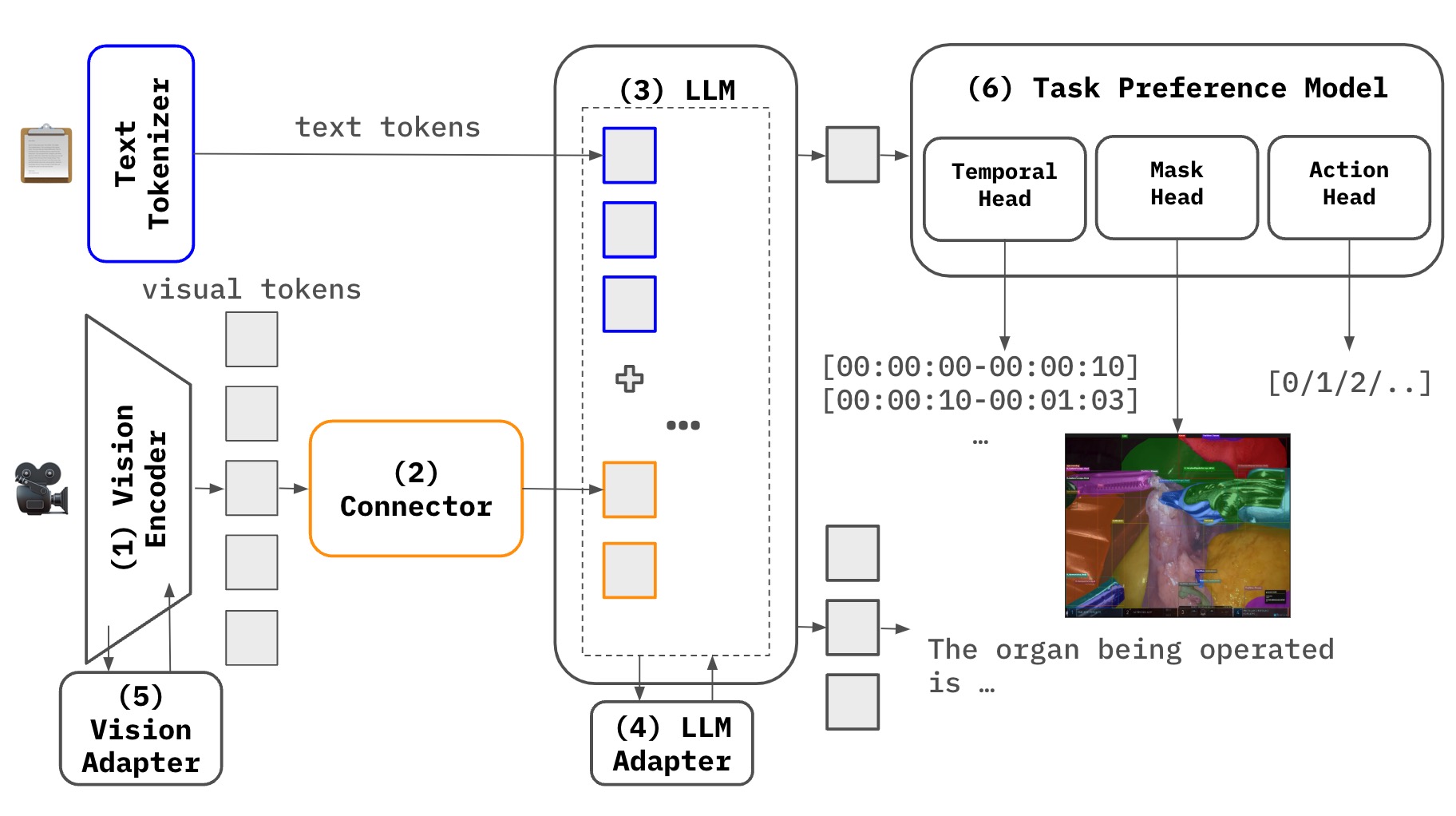 Fig. 5: VLA for Surgical Navigation
Fig. 5: VLA for Surgical Navigation
One of the most critical challenges in Multimodal Large Language Model (MLLM) research lies in effectively achieving crossmodal alignment among different modalities (e.g., video and text). In particular, when dealing with long sequential data such as surgical videos, not only do we need to understand the overall scene, but we also require an advanced approach to capture the fine-grained details contained within.
Task Preference Optimization (TPO)
Task Preference Optimization (TPO) was recently introduced to address fine-grained vision task learning by incorporating task tokens and a multi-task architecture. By leveraging detailed labels (e.g., object locations or specific properties) from video data, the model can acquire substantially more fine-grained visual information, enabling co-training across multiple vision tasks. For example, different tasks such as object detection, segmentation, and action recognition reinforce each other, ultimately enhancing the model’s overall multimodal representation capacity.
InternVideo2.5 & Long-Rich Context (LRC) Modeling
InternVideo2.5, a follow-up to TPO, extends the multi-task architecture by focusing on more effectively capturing long temporal information and fine-grained visual context (LRC: Long and Rich Context). Through preference optimization that directly associates dense vision task annotations (e.g., segmentation labels) with the model, along with adaptive hierarchical token compression, InternVideo2.5 achieves:
- A model structure capable of retaining and interpreting sequences at least six times longer,
- The capacity to handle fine-grained tasks like object tracking and segmentation.
As a result, it excels at managing the complex context in lengthy sequential scenarios (e.g., surgical videos) and offers a deep understanding of multiple objects or anatomical structures within surgical scenes.
Addressing Data Scarcity & High Training Costs with BT-Adapter
Medical video data is notably limited due to data scarcity and privacy constraints, making large-scale training particularly challenging. Moreover, in the LLM era, acquiring sufficient high-quality textual annotations remains a significant hurdle—often hindering visual-instruction tuning. BT-Adapter offers a breakthrough approach to mitigate these issues by:
- Maintaining the image-language pretrained backbone (e.g., CLIP or another vision encoder) in a frozen state,
- Adding and training a lightweight Branching Temporal Adapter module to effectively capture temporal information from video.
This method achieves strong performance without requiring additional video instruction tuning, thereby reducing training costs and data requirements.
An MLLM Architecture for Surgical Navigation
Our goal is to maximize performance for surgical navigation through the following architecture:
-
TPO-based Multi-task Structure + InternVideo2.5’s LRC Approach
- Incorporate a temporal understanding head and an instance segmentation head to handle long temporal sequences while precisely capturing detailed anatomical information.
- Leverage direct preference optimization and token compression techniques to simultaneously learn fine-grained vision tasks and enhance memory capacity for extended sequences.
-
Action Head (Navigation View Switching)
- In addition to comprehending visual content, introduce an action head capable of learning and predicting surgical decisions/actions needed in real scenarios.
- This enables automated or semi-automated navigation view transitions, which can be seamlessly applied to surgical navigation systems such as SP-NAS.
-
BT-Adapter
- Deploy a lightweight module to address data scarcity and training cost issues.
- Capture temporal context from surgical videos without additional video instruction tuning.
By integrating these components, we can track and analyze complex procedures and fine-grained anatomical changes over extended surgical videos, ultimately enhancing real-time decision-making and high-precision surgical assistance. Notably, this architecture alleviates the constraints of limited data, improves multimodal understanding, and advances automated navigation—all critical for a high-performance MLLM in clinical settings.
Implementation & Training Strategy
Building on our proposed MLLM architecture that combines InternVideo2.5 with BT-Adapter to deliver an interpretable surgical navigation system capable of handling the complexity and long temporal context of surgical videos, we now detail its training strategy from the perspective of loss functions.
1. Combined Architecture: BT-Adapter + InternVideo2.5
-
InternVideo2.5
- This framework primarily consists of two key components:
- Video-Text Alignment and Multimodal LLM training,
- Task Preference Optimization (TPO) for fine-grained spatiotemporal tasks (e.g., temporal grounding, segmentation, tracking).
- By employing token compression (HiCo), segment pooling, and multi-stage training, InternVideo2.5 achieves both “long-form video comprehension” and “precise visual recognition.”
- This framework primarily consists of two key components:
-
BT-Adapter
- The existing video encoder (e.g., the InternViT within InternVideo2.5) is frozen, and a branch-shaped “temporal module” is added and trained independently.
- Through asymmetric masking and three specialized losses (VTC, MBTA, MBCA), this approach efficiently captures temporal information with minimal computational overhead.
By integrating these two methods, we retain the multimodal and long-form video capabilities already learned by InternVideo2.5 while introducing BT-Adapter to bolster temporal modeling, thereby enabling a more detailed understanding of surgical scenes.
2. Base Loss and TPO in InternVideo2.5
In InternVideo2.5, video-text alignment, LLM instruction tuning, and Task Preference Optimization (TPO) are used to learn multimodal representations.
-
Base Loss
- Encompasses the fundamental alignment between video and text, as well as multimodal LLM training.
- Employs a wide range of data, including short/long videos, images, and text.
-
Task Preference Optimization
- Facilitates fine-grained spatiotemporal tasks (e.g., tracking, segmentation) by utilizing an additional Task Head or Preference Model.
- Minimizes the error between the model’s predictions and the labels (or preference scores) for each specialized task.
Overall, the InternVideo2.5 loss function can be expressed as:
3. Three Losses for BT-Adapter (VTC, MBTA, MBCA)
BT-Adapter adopts a branch structure specifically for temporal learning and applies asymmetric masking only to that branch. Leveraging three separate losses, the method aligns and reconstructs masked tokens relative to the frozen backbone (InternViT) or text embeddings.
-
Video-Text Contrastive (VTC)
- Conducts contrastive learning between the video embedding vv (from the masked branch output) and the text embedding tt.
- Expands time-specific embeddings on top of the existing video-text alignment offered by InternVideo2.5.
-
Masked Branching Token Alignment (MBTA)
- Aligns the branching tokens () with the frozen backbone output (InternViT).
- Bridges spatiotemporal representations between the temporal branch and the backbone’s extensive visual knowledge.
-
Masked Branching Cross-Modal Alignment (MBCA)
- Performs contrastive learning between the branching tokens () and the text embedding .
- For example: .
- Ensures that branch patches, which include temporal features, also align directly with textual descriptions.
4. Final Loss Composition: InternVideo2.5 + BT-Adapter
Ultimately, we must combine the Alignment + TPO losses from InternVideo2.5 with the VTC + MBTA + MBCA losses from BT-Adapter. One possible formulation is:
- and are hyperparameters controlling the relative weight of each loss.
- addresses video-text alignment and overall LLM training.
- BT-Adapter introduces time-focused embeddings ().
- TPO () refines additional spatiotemporal tasks such as tracking or segmentation.
Conclusion
In this project, we designed and implemented an MLLM architecture that combines InternVideo2.5 and BT-Adapter to achieve Interpretable Surgical Navigation. Specifically, we integrated:
- Long-form video alignment (Alignment) and LLM tuning as well as Task Preference Optimization (TPO) offered by InternVideo2.5,
- Lightweight, time-focused learning (Asymmetric Masking + VTC, MBTA, MBCA) from BT-Adapter,
through a comprehensive loss formulation that enables the simultaneous handling of long-duration surgical videos and fine-grained spatiotemporal tasks (e.g., temporal understanding, instance segmentation, action).
This approach is particularly effective for the complex, extended temporal data found in surgical procedures, maximizing the potential of MLLM while supporting decision-making (actions) and reliable navigation in the clinical environment.